pocket-random 要實作的功能有:
- 隨機顯示文章
- 對 1 做排程與規劃
- 統計、顯示成就
這篇文章主要紀錄 隨機顯示文章 這個功能的資料結構思考過程。
話說,為什麼要思考這樣的東西,原因是需要確定資料庫的資料格式,同時也是要整理程式的流程。
考量整體之後再決定資料結構,以免寫到一半又要大改。
我怎麼會說又呢orz
隨機顯示文章 + 排程規劃
我手上會有的資料:
使用者儲存在 Pocket 帳號的所有文章及其屬性。
要實現的功能
每天設定多個領域,每個領域隨機選出文章
e.g : 比如每天都看 javascript 的文章 2 篇、CSS 的文章 1 篇。星期一~日 可以做不同的設定
由於要統計每日看完的文章,必須要判斷使用者「已看完」文章。
初步構想
功能 1 :
Pocket 可以對文章加上 tag,所以可以透過文章的 tag 判斷一個文章屬於甚麼領域。
比如 「每天選出有 javascript tag的文章 1 篇」功能 2 :
用個星期一~日的作為key的物件,value 用陣列放功能 1 設定的條件就行。功能 3 :
使用「封存」(archive) 或設定特定標籤(e.g : random-readed),這個特定標籤可以使用者自訂。
之所以可以用封存去標示,是考慮也許有使用者比較習慣用封存的功能。
考慮各種可能
一個文章的 tag 可能有很多個。
比如:「vue、前端、javascript」、「後端、vue、Node.js」、「後端、php、資料庫」……..
試著想像一下,如果我想要集中看 vue 的文章,每天前端 2 篇、後端 1 篇,只用一個 tagvue是不夠的。要能設定複數的 tag 才行。比如:
「vue、前端,2 篇」
「vue、後端,1 篇」
也有一個想法是使用者自己去自己的 Pocket 整理 tag。可是如果使用者文章很多,tag又很複雜,叫人先整理再來用,好像太霸道了。承1,也有可能會這樣:
「我想要看美食或是旅遊的文章,每天 2 篇 ~ 」
「我想要看html、vue或是html、jQuery的文章,每天 2 篇」
雖然沒有根據,但使用者說不定會想這樣篩。
考慮到例外情況2時,從舉例的句子中浮現一個可能的資料結構:
「我想要看 html、vue 或是 html、jQuery 的文章,每天 2 篇」
=>「篩出 tag 有 html 且 vue 或 html 且 jQuery 的文章」
=> [['html','vue'],['html',jQuery]]
因為 tag 變成複數的,所以先前提到 某某領域 的定義就不能用 tagName,而是交由使用者自己定義。
所以使用者設定好 某領域的文章出現幾篇 ,其背後的資料結構如下:
{
name : 'practice1',
filter : [['html','vue'],['html','jQuery']],
targetNum : 2
}- 同一個領域,每天的目標篇數可能不同。
在寫這個文章的時候想到這個可能情況:
星期一到日,每天可以對同一領域設定不同的目標。
直覺想的話,可以這樣表現:
'Monday' : [
{
filter : ['parctice1'],
targetNum : 2
}
]
// filter
'practice1' : {
filter : [['html','vue'],['html','jQuery']]
}之後就可以根據今天星期幾,去取得對應的 filter。
- 出現相同名稱的 filter :
這裡要提的狀況是,使用者曾經命名一個 practice1 的 filter,用了一段時間後,他想要修改 filter 的條件。於是就會出現不同條件,名稱卻相同的狀況。
只在篩選資料的用途上,可以在演算的過程排除掉相同的 filter。
但是這個程式有統計的需求,不同時期(不同條件)的 practice1 要如何區別呢?
模擬 filter 的演算狀況
filter 的形式就是:const filter = [['html','vue'],['html','jQuery']]
它儲存的是一串條件,要用這個條件篩出一串符合的文章,再從符合的文章中做隨機選取。
底下是文章們的範例資料:
let articles = [
{ title: "文章1", tags: ["html","vue"] },
{ title: "文章2", tags: ["css","vue","動畫"] },
{ title: "文章3", tags: ["html","jQuery","Web API"] },
// .......................
]範例的 filter 邏輯是:
找出 tag 中同時有 html , vue 標籤,或者同時有 html, jQuery 標籤,的文章。
用原生 js 寫可以這樣:
let result = []
articles.forEach(article =>{
if (isArticleMatch(article,filter)){
result.push(article)
}
})
function isArticleMatch(article,filter){
for (var i=0;i<filter.length;i++){
let situation = filter[i];
if (isMatchSituation(article,situation)){
return true
}
}
return false
}
function isMatchSituation(article,situation){
for (var i=0;i<situation.length;i++){
var hasTag = article.tags.includes(situation[i])
if (!hasTag){
return false
}
}
return true
}可行,可是
易讀性有點差。除了套第三方函式庫改進之外,或許可以將 filter 打包成物件去處理。
以上面的例子來說,html 這個條件兩個 situation 都有,所以 html 這個條件篩了兩次,能不能只篩一次呢?
我試著改成這樣// 原本 'practice1' : { filter : [['html','vue'],['html','jQuery']] } // 修改 'practice1-2' : { filter : [['html','vue'],['html','jQuery']], internal : ['html'], spec : [ ['vue'],['jQuery'] ] }
保留原始使用者設定的狀況,然後另外製作演算用的資料。
分析出兩個 filter 都有 html 這個條件,先比對這個共通條件,然後再比對各個獨特條件 spec。
let filter = {
filter : [['html','vue'],['html','jQuery']],
internal : ['html'],
spec : [ ['vue'],['jQuery'] ]
}
let result = []
articles.forEach(article =>{
if (isArticleMatchInternal(article,filter) && //新增
isArticleMatchSpec(article,filter)){
result.push(article)
}
})
function isArticleMatchInternal(article,filter){ //新增
for (var i=0;i<filter.internal.length;i++){
var hasTag = article.tags.includes(filter.internal[i])
if (!hasTag){ return false }
}
return true
}
function isArticleMatchSpec(article,filter){
for (var i=0;i<filter.spec.length;i++){
let situation = filter.spec[i];
if (isMatchSituation(article,situation)){
return true
}
}
return false
}
function isMatchSituation(article,situation){
for (var i=0;i<situation.length;i++){
var hasTag = article.tags.includes(situation[i])
if (!hasTag){
return false
}
}
return true
}還算能用吧…,要想辦法解決易讀性問題。
結論
從以上過程可以得出資料流動的狀況如下: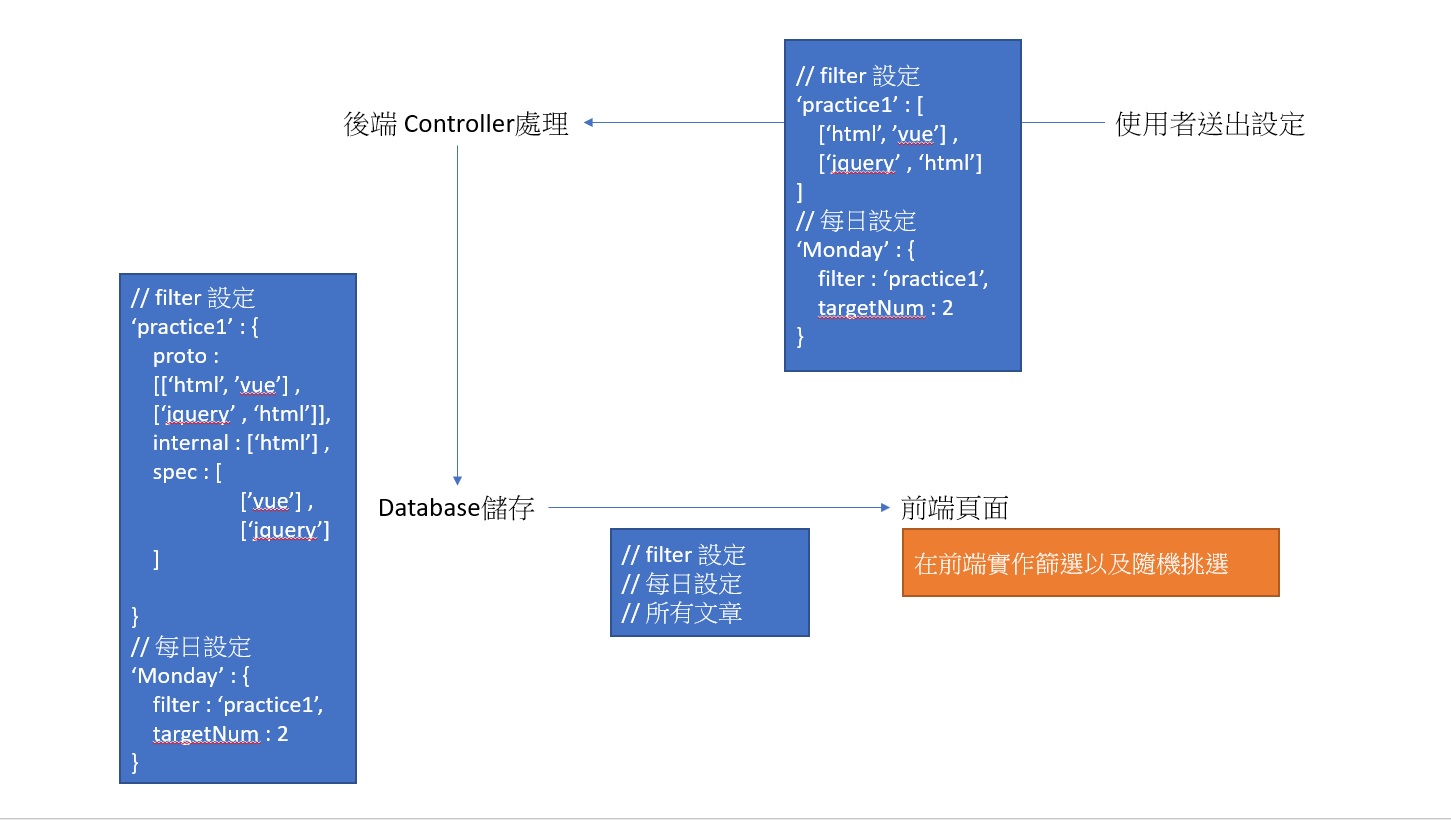
這麼一來就確定了:
- 使用者設定的每個領域篩選條件該如何儲存?
- 大概該如何去實作出來,會遇到甚麼問題?
所以可以開始設定 (一部分) 資料庫的格式了。
欠缺且需要額外處理的部分是:
- 如何解決易讀性的問題?
- 如何用資料表示星期幾?
- 如何實作隨機選取?
尾巴
其實還有一部分是關於統計用的資料格式,思考過程也是又臭又長的,就不多提了。
有沒有人能把這篇看下去我也是很好奇…。
我發現滿有趣的部份是,統計用的資料格式跟這部分資料如何表現,這兩個很可能不會互相影響。但如果更動更根本的定義,兩個都會一起改。比如說,上面提到一個在寫文章的時候才想到的狀況:我原本設想,目標篇數跟filter綁定在一起,因filter而異。但後來想到,實際上可能需要每天不一樣,所以應該是因時間而異才對。這導致兩邊原本想好的格式一起改動。
相對的,不管我怎麼修改 filter 的格式,都不會改變統計用的資料格式。
我在想這個原因應該是,前者我是變更更根本的遊戲規則,後者我只是改變形式而已。所以或許我之後可以先從遊戲規則的定義開始整理起吧。
有個值得反省的部分是,我並沒有明確的設定使用者是怎麼樣的人,如果是要專案開發的話,果然還是要稍微做個功課吧?